Question 1.¶
What is the fundemental idea behind "Maximal Margin Classifiers" (as well as their extensions "Support Vector Classifier" and "Support Vector Machines")?
Question 2.¶
What is a support vector?
Question 3.¶
In the plot below, which points are the "support vectors"?

Click here for answer
It uses more than 1 here for each class, although which ones are quite tricky to discern. Don't worry if you got a few of the points wrong here, the main thing is to note that sometimes it can be more than one point per class!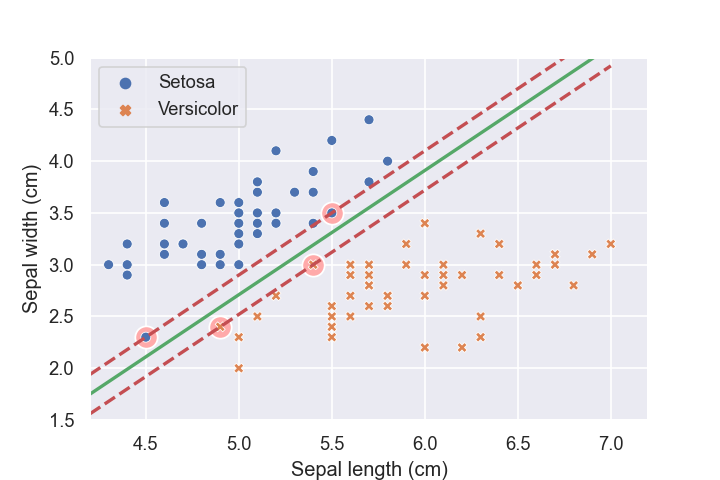
Question 4.¶
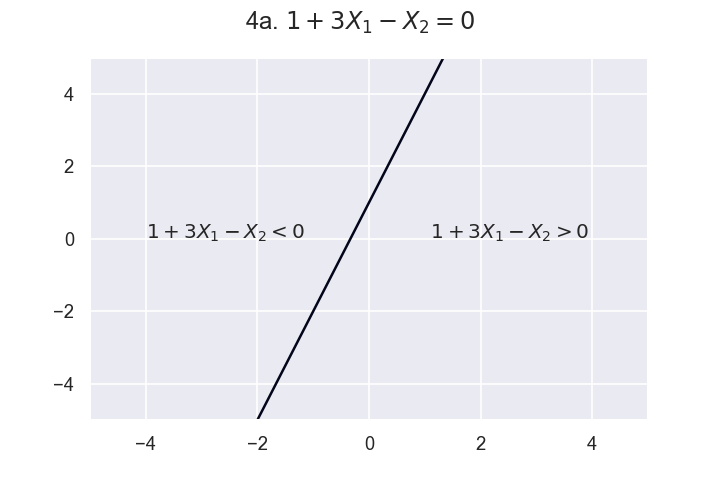
Sketch or code (using Python) the following two dimensional hyperplanes, indicating where $1 + 3X_1 - X_2 > 0$ and where $1 + 3X_1 - X_2 < 0$.
a. $1 + 3X_1 - X_2 = 0$
Click here for answer
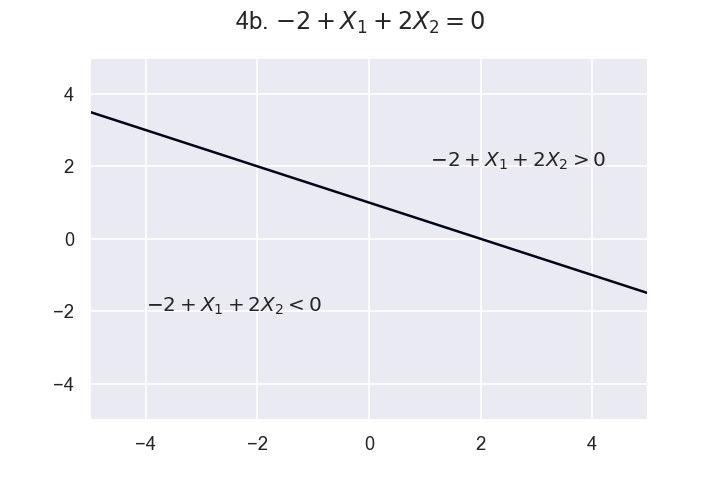
b. $-2 + X_1 + 2X_2 = 0$
Click here for answer
Question 5.¶
Fundamentally, how are "Support Vector Classifier" and "Support Vector Machines" extensions of "Maximal Margin Classifiers"?
Question 6.¶
If $C$ is large for a support vector classifier in Scikit-Learn, will there be more or less support vectors than if $C$ is small? Explain your answer.
Question 7.¶
Is the "confidence score" output from a SVM classifier the same as a "probability score"?
Question 8.¶
Say you trained an SVM classifier with an RBF kernel. It seems to underfit the training set: should you increase or decrease $\gamma$ (gamma) and/or $C$?